A local-HPC workflow-management broker, built on just Postgres
I just released queue_workflows under MIT — a standalone, pip-installable workflow-management broker for a local, self-hosted HPC. The pitch is one sentence: the only hard runtime dependency is Postgres. No Redis, no RabbitMQ, no Celery, no Sidekiq, no separate message broker to run, monitor, back up, and reason about during an incident.
It started life as “Phase 6” inside a private production stack and got extracted so a fleet of sibling services could share one DRY engine instead of each carrying a copy. This post is about why the design lands where it does — the no-broker bet, and what you have to get right to make Postgres a credible queue.
Local-cluster swift management: that’s the point of it — the engine is built to swiftly manage a local, self-hosted cluster of a handful of heterogeneous CPU/GPU machines, and squeeze the most out of limited resources. You turn a given machine’s worker on or off on demand, and load or unload models across different boxes as the work shifts, so a job lands on whatever capacity is free instead of being pinned to one host that’s busy or down. The goal is to quickly build that elastic, jump-on-free-resources behaviour on hardware you already own, without standing up a cluster scheduler.
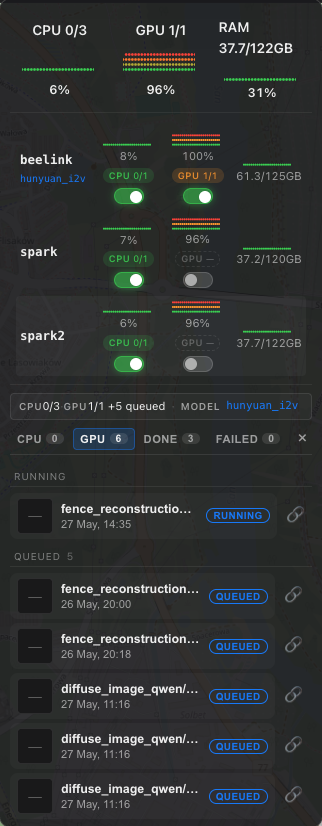
That dashboard isn’t part of the package — the engine just emits the telemetry (more on that at the end). It’s the easiest way to see what the engine is doing, so I’m leading with it.
The shape of the system is three plain processes pointed at one database. Nothing talks to anything else directly — every interaction is a row written to, or read from, Postgres:
SKIP LOCKED, and the orchestrator drains the outbox and reclaims lapsed leases. Recreated from the repo's architecture diagram.Why a broker is a tax you might not need
The reflex for “I need a job queue” is to reach for Redis + a worker framework. That’s the right call at a certain scale. But it buys you a second stateful system alongside the database you already run: another thing to provision, secure, fail over, and keep consistent with your domain data. The classic bug is the gap between the two — you commit a row to Postgres, then enqueue a job to Redis, and the process dies in between. Now you have a row with no job, or a job with no row.
If your workload already lives in Postgres, the database can be the queue, and that gap disappears. The enqueue and the domain write happen in one transaction. The cost is that you have to implement the queue mechanics carefully — which is exactly what the engine packages up.
The claim: SKIP LOCKED + LISTEN/NOTIFY
INSERTing a row is enqueuing the work. Claiming the next job is a single statement:
UPDATE workflow_node_jobs
SET status = 'running',
claimed_by = $1,
lease_expires_at = now() + interval '30 seconds'
WHERE id = (
SELECT id FROM workflow_node_jobs
WHERE status = 'queued' AND queue = $2
ORDER BY priority DESC, id
FOR UPDATE SKIP LOCKED -- the magic words
LIMIT 1
)
RETURNING *;FOR UPDATE SKIP LOCKED is the load-bearing clause. Each worker locks a claimable row and skips any row another worker already locked, so N workers claim N distinct jobs with zero coordination and no lost-update races. It’s been in Postgres since 9.5 and it’s the single feature that makes this whole approach viable.
The other half is latency. Polling a table in a tight loop is wasteful and slow; instead, a trigger fires pg_notify('node_job_ready', <queue>) inside the writer’s transaction, and each worker does LISTEN node_job_ready and sleeps until it’s woken. Because the NOTIFY rides the inserting transaction, there’s no “row is queued but nobody got woken” window. A 1-second safety poll sits behind the LISTEN purely to cover a dropped notification — belt and suspenders.
One subtlety worth stating: the claim’s ORDER BY is assembled only from validated integers and fixed SQL fragments, never from caller-supplied strings. A queue that builds its ordering from user input is a SQL-injection foot-gun; don’t.
Liveness: leases, not heartbeated jobs
A worker that claimed a job can crash, wedge, or get OOM-killed. How does the work come back?
The engine uses leases. A live worker renews lease_expires_at roughly every 10 seconds while a job runs, so the lease length is decoupled from job duration — a 40-minute render and a 40-millisecond task use the same 30-second lease. A dead worker simply stops renewing; its lease lapses; an orchestrator reclaim sweep flips the row back to queued (re-firing the NOTIFY). That sweep is the sole recovery path for an orphaned running row, which makes the recovery story easy to reason about: there’s exactly one.
running row back to queued.On top of leases, each claimed job is bracketed by two watchdogs:
- a wall-clock watchdog that hard-exits the process when a job blows its time budget;
- an opt-in no-progress (stall) watchdog for GPU work, which stays inert during a slow model load and only arms after the first per-step progress beat — so a legitimately long cold-start is never mistaken for a hang.
Both watchdogs work by killing the process, not by trying to interrupt the in-flight code. That’s deliberate: a wedged CUDA kernel won’t honour a cooperative cancel flag, and the OS tearing down the process is the only thing that reliably frees the RAM/VRAM. The lease then lapses and reclaim re-queues the job elsewhere. This is why one worker is one process holding one job — a hard exit kills exactly the hung work and nothing else.
DAG dispatch and the durable outbox
Beyond standalone jobs, the engine runs DAGs: a node finishes, and its downstream nodes become eligible once all their dependencies are completed or skipped. The tricky part is coupling the worker (which finished the node) to the dispatcher (which fans out the next ones) without making fan-out a synchronous, failure-prone RPC.
The answer is the transactional outbox pattern. When a worker finalizes a node it writes, in one transaction, both the terminal status and a workflow_dispatch_events row. A separate orchestrator loop drains that outbox and runs the fan-out. So:
- fan-out is retryable — a failing dispatch callback is retried on the next tick, and poison-flagged after a max attempt count;
- the worker is never blocked on downstream bookkeeping;
- there’s no lost event, because the event and the state change commit atomically.
The DAG-walk logic is pure and unit-testable with no worker pool in sight; the durability comes entirely from “write the event in the same transaction as the state.”
Two job families, one database
The engine carries two independent job shapes, each with its own table and claim path:
| DAG node-jobs | Ingest jobs | |
|---|---|---|
| Table | workflow_node_jobs | ingest_jobs |
| Queues | cpu, gpu | host-defined (e.g. fetch, load, …) |
| Shape | fanned out from a DAG run | standalone, periodic or parametrised |
| Enqueued by | the dispatcher | a PG-native scheduler, or directly by the host |
The ingest path is multi-tenant: a second consumer can route its own queue names and attach per-job arguments, with the queue allow-list and task names validated host-side rather than baked into a DB CHECK. Enqueuing accepts a caller-supplied connection, so the NOTIFY again rides the host’s own transaction — the same atomicity guarantee as the DAG path.
The GPU angle
The original workload was GPU inference, which shaped three features you don’t usually find in a job queue:
- A warm-model cache. The GPU worker keeps one model resident across same-model jobs; the claim adds a warm-model affinity tiebreak so a job needing the already-loaded model sorts first. Reloading a multi-GB model per job is the dominant cost; this kills it.
- Health-gated watchdogs. A wall-clock budget alone can’t catch a GPU that’s wedged at 0% utilisation but hasn’t timed out yet. The stall watchdog watches progress beats, and there’s a last-resort orchestrator-side detector for a hardware hang that freezes the in-process watchdog threads themselves.
- An operator ON/OFF control plane. You can hard-stop or park a single
(host, queue)worker by writing one row — it requeues its in-flight job (redistributing, not failing it), frees VRAM, and comes back parked until turned on. That’s the row of toggles in the dashboard above.
Operating it
It’s the boring part, which is the point. Three process roles — an orchestrator (migrations + dispatch + reclaim), claim workers (one process each), and a scheduler — all pointed at the same database:
pip install git+https://github.com/robertziel/python_workflows_queueimport queue_workflows
queue_workflows.configure(db_url_env="MY_DB_URL") # everything else has a safe default
queue_workflows.db.bootstrap() # idempotent migration chain
queue_workflows.claim_worker.main(["--queue", "gpu"])Everything domain-specific is an injected hook with a default, so import + configure() + a reachable Postgres runs end-to-end. The package imports nothing from any host app — enforced by a test.
For observability, each host samples CPU/GPU/RAM and emits a snapshot via pg_notify('hw_metrics', …); workers upsert worker_heartbeats; queue depth is a SELECT … GROUP BY status. Point a small front-end at those three signals and you get the dashboard at the top of this post. The engine ships the data; the UI is yours to build (this is a great task to hand to a coding agent — point it at the hw_metrics notifications and the snapshot helpers and let it wire up the view).
When not to do this
To be honest about the trade: Postgres-as-a-queue is excellent up to a healthy throughput ceiling and when your jobs already live next to your data. If you’re pushing millions of tiny messages per second, or you need fan-out to many independent consumers, or your jobs have nothing to do with your relational data, a purpose-built broker earns its keep. The win here is operational: one system, one backup, one set of credentials, one transactional boundary — and SKIP LOCKED doing the heavy lifting.
Code and full design docs are on GitHub. It’s MIT — take it apart.